Searchable field-level encrypted customer PII with k-anonymity
Author: Alessandro Colomba
Introduction
GEICO stores personally identifiable information (PII) about customers that is necessary for its insurance business. This information is legitimately needed to forge contracts with legal persons and manage insurance risk.
In the hands of malicious actors, this information may lead to identity fraud, so GEICO strives to protect the confidentiality of PII with a comprehensive array of security measures. Some are administrative in nature, such as processes around handing sensitive information or secure coding practices; others are technical, such as secure networking, vulnerability scanning, pen testing, robust access control, or at-rest encryption.
Field-level encryption
Field-level encryption is one such data protection measure that GEICO broadly deploys. In this scheme, only individual data fields that contain sensitive data are encrypted. Consider, for example, a JSON record that holds an email address:
{
"id": "qzx7JhErcT1SpqX_KSnHPBP37lwfW5Iz",
"emailAddress": "alice@example.com"
}With field-level encryption, the record becomes:
{
"id": "qzx7JhErcT1SpqX_KSnHPBP37lwfW5Iz",
"emailAddress": "YWxpY2VAZXhhbXBsZS5jb20rc2VjcmV0"
}This approach adds an extra layer of security on top of other data protection schemes such as disk, filesystem, or database encryption. These schemes protect data at rest but expose plaintext data if an unauthorized party gains access to a live disk, filesystem, or database. By contrast, with field-level encryption, an unauthorized party only sees ciphertext for each field.
A major benefit of making applications responsible for encryption and decryption is that they can keep data encrypted throughout its lifecycle. Applications briefly decrypt data only when they need to process it, such as validating an email address or sending an email. Data is otherwise transmitted and stored encrypted in memory and at-rest.
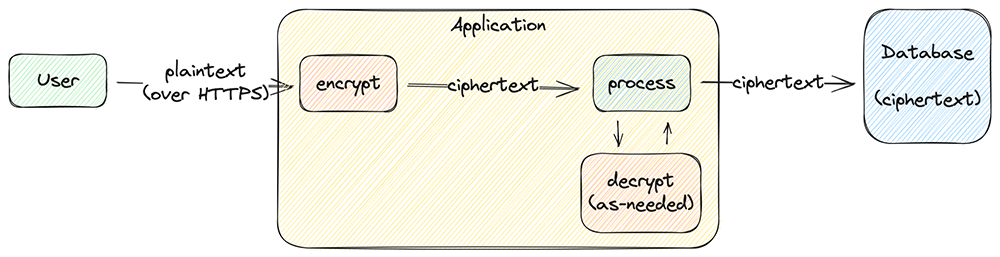
What gets encrypted, stays encrypted.
Keeping data encrypted narrows the focus of data protection to distributing access keys to consumers. Security requirements in other systems are reduced because they only process encrypted data. For instance, encrypted data can be safely logged, can be transmitted over insecure channels, and is intrinsically resistant to tampering.
Searching field-level encrypted data
Searching encrypted data is another demand that field-level encryption imposes on applications, because encryption keys are periodically rotated.
For example, to find a record by a specific email address, consumers might naively encrypt the search term and look for a match in a database:
email = 'alice@example.com'
customers = db.select(
'SELECT * FROM customers WHERE emailAddress = $1',
encrypt(email, key); # encrypted search termSELECT *
FROM customers
WHERE emailAddress = "YWxpY2VAZXhhbXBsZS5jb20rc2VjcmV0"This approach is impractical because when keys rotate, the same plaintext data encrypts to a different ciphertext. When a search term is encrypted using the current key, its ciphertext will not match the value encrypted with an earlier key. Over a sufficiently extended period, the ciphertext for a specific plaintext is effectively non-deterministic.
A different strategy for indexing encrypted data is needed, such that consumers need not know the right encryption key before searching.
Indexing encrypted data
A practical scheme for indexing encrypted data is to store a collision-resistant, deterministic digest of the plaintext alongside the ciphertext.
{
"id": "qzx7JhErcT1SpqX_KSnHPBP37lwfW5Iz",
"emailAddress": {
"val": "YWxpY2VAZXhhbXBsZS5jb20rc2VjcmV0",
"idx": "F634F155207086FA9B7525C11E74BEC39722ADF296B07959E56929F0D1C48AFD"
}
}Hash functions are one-way, so the original plaintext is unrecoverable from the digest. Consumers can use the digest of the search term as a query predicate:
email = 'alice@example.com'
customers = db.select(
'SELECT * FROM customers WHERE emailAddress.idx = $1',
hash(email); # hashed search termSELECT *
FROM customers
WHERE emailAddress.idx = "F634F155207086FA9B7525C11E74BEC39722ADF296B07959E56929F0D1C48AFD"While this method is effective for unguessable data, some types of data are vulnerable to dictionary attacks. For example, databases of compromised email addresses are widely available. Given the low computational cost of deterministic hash functions, an attacker can identify emails using the digest alone, circumventing the need to decrypt entirely.
K-anonymized indexes
K-anonymization, or bucketization, is a technique formally examined in Bellare [bb] that has received recent visibility through the Pwned Passwords service [pp] [cf] and the AWS searchable encryption offering [se].
This is accomplished by truncating the digest indexes to a strategically selected number of most significant bits. Many records with different values end up sharing the same index, effectively generating collisions.
{
"id": "qzx7JhErcT1SpqX_KSnHPBP37lwfW5Iz",
"emailAddress": {
"val": "YWxpY2VAZXhhbXBsZS5jb20rc2VjcmV0",
"idx": "F63"
}
},
.
.
.
{
"id": "dmk7WuRepG1FcdK_XFaUCOC37yjsJ5Vm",
"emailAddress": {
"val": "Ym9iQGV4YW1wbGUuY29tK3NlY3JldA==",
"idx": "F63"
}
}Even if an attacker is equipped with a dictionary of email addresses, each attempt yields multiple false positives, reducing their ability to identify specific records.
Authorized consumers search by the truncated index and then sift through false positives by decrypting the ciphertext and discarding records that don't match the original search term.
email = 'alice@example.com'
customers = [c for c in db.select(
'SELECT * FROM customers WHERE emailAddress.idx = $1',
trunc_hash(email)) # hashed search term, truncated
if decrypt(c.emailAddress.val) == email] # filters out false positivesSELECT *
FROM customers
WHERE emailAddress.idx = "F63"Bucketed indexes function similarly to Bloom filters. Searches may yield false positives, or only false positives. Only the absence of results conclusively indicates that the record is absent.
This method addresses the issue of key rotation, as it doesn't require consumers to know the encryption key before searching. When consumers receive encrypted search results, a key identifier embedded within each ciphertext guides them to pick the correct decryption key.
Operational considerations
Figuring out the optimal number of bits to retain in truncated digests requires striking a balance between security and performance. Reducing the number of bits increases the size of the buckets, which leads to more false positive search results.
Both the Ciphersweet library [cs] [cstm] and AWS [bcn] recommend choosing a truncated hash length such that the number of collisions ranges between two and the square root of the number of possible values.
Using the AWS notation where a beacon represents the truncated digest, the minimum and maximum beacon length—the number of most-significant bits to retain—can be calculated from the number of expected distinct values:
The number of expected collisions can be estimated for different beacon lengths in the range:
Increasing the number of returned search results by a factor of 10x, 20x, or more may appear prohibitively inefficient, but the actual impact depends on access patterns.
In some systems, queries make up a small fraction of the overall workload, making the extra cost negligible. In other systems, some queries consult many shards but only need to return a single result; assuming a uniform distribution of records across shards, the added cost of returning false positives from each shard may be insignificant.
Determining the balance between security considerations and operation costs with bucketized indexes requires a holistic understanding of the system and iterative experimentation.
Conclusion
As a competitive player in the insurance market, GEICO's success relies on the trust of its customers, making the protection of personally identifiable information imperative.
GEICO deploys field-level encryption at scale despite the operational complexities this model entails, one being secure searches. Striking a balance between safeguarding customer personal information and managing operational concerns is challenging, yet vital.
References
[bb] Bellare, Mihir; Boldyreva, Alexandra; O'Neill, Adam (2007). "Deterministic and Efficiently Searchable Encryption." Advances in Cryptology - CRYPTO 2007. Lecture Notes in Computer Science. Vol. 4622. pp.535–552. doi: 10.1007/978-3-540-74143-5_30. ISBN 978-3-540-74142-8.
[pp] Hunt, Troy. "Understanding Have I Been Pwned's Use of SHA-1 and k-Anonymity." Have I been Pwned, 30 June 2022, https://www.troyhunt.com/understanding-have-i-been-pwneds-use-of-sha-1-and-k-anonymity/.
[cf] Ali, Junade. "Validating Leaked Passwords with k-Anonymity." Cloudflare, 15 June 2020, https://blog.cloudflare.com/validating-leaked-passwords-with-k-anonymity.
[se] "Searchable encryption." Amazon, https://docs.aws.amazon.com/database-encryption-sdk/latest/devguide/searchable-encryption.html.
[cs] "CipherSweet." Paragon Initiative Enterprises, https://ciphersweet.paragonie.com/.
[cstm] "Security Properties and Threat Model for CipherSweet." Paragon Initiative Enterprises, https://ciphersweet.paragonie.com/security.
[bcn] "Choosing a beacon length." Amazon, https://docs.aws.amazon.com/database-encryption-sdk/latest/devguide/choosing-beacon-length.html.